CppCon 2017: When a Microsecond Is an Eternity: High Performance Trading Systems in C++
这是今天刷 v2ex 的时候看到的一个 tech talk,讲的是 c++在高频交易下的使用,我以前看过《漫步华尔街》,了解过一点高频交易的原理,这个tech talk 主要讲了一下什么是电子做市,有哪些技术挑战,以及如何利用 c++ 解决这些挑战。
什么是电子做市?
The elements of good trading are: (1) cutting losses. (2) cutting losses, and (3) cutting losses. If you can follow these three rules, you may have a change.
- Ed Seykota
做市商的主要活动:
- 为市场提供最新的价格
- 找出获利的机会
说到底,做市商的存在是为市场提供流动性,并在这流动性中找到获利的机会。
主要目标:
- 稳定做出小的可获利的交易
- 避免做出大的不好的交易
抛开具体价格不谈,一个成功的交易算法需要做到低价买入、高价卖出。在市场竞争中,在任何时候都要更快。
在交易过程中,资金安全是最重要的,交易市场是一个完全混沌的系统,所有的订单都有可能在很短的时间内转为错误的走向,所以需要自动去检查失败的交易。
技术挑战
- Hotpath只会在 0.01%的时间中活跃,剩下的时间,系统往往处于空闲状态,或者单纯执行一些管理工作
- 操作系统、网络和硬件都专注于吞吐量和公平性。
- 抖动是不可接受的,这意味着不好的交易
整体而言,交易系统的性能最好不能太大的方差,整体平均性能最好大于中位水平,这样的系统就是一个好的交易系统。
C++ 在交易系统中扮演的角色
C++能够以接近于 0 的开销实现对硬件层的抽象。但是在实际生产中,还有其他的一些因素:编译器、机器架构、第三方库、编译时的标志位等会影响C++在机器指令层面的实际操作。
这里有一个网站(https://godbolt.org/),可以将 C++ 编译成汇编语言,这样我们就能知道这些语句正在做什么。
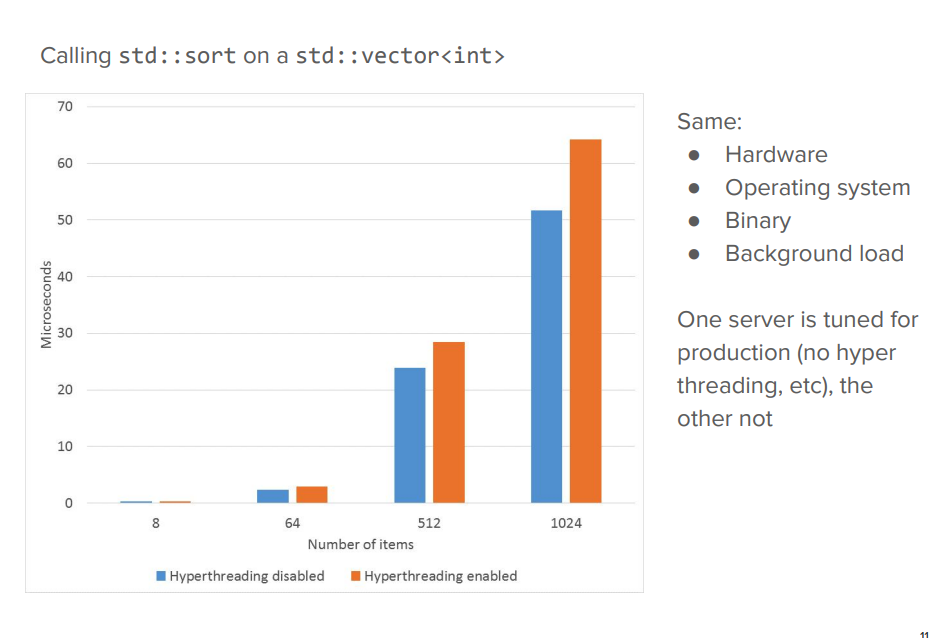
上图是对 vector执行sort操作时是否开启超线程的性能对比。可以看到,开启超线程之后,sort操作反而变慢了。
1 | 超线程(Hyperthreading),也被称为超线程技术,是一种在单个物理处理器核心内部模拟出多个逻辑处理器的技术。它旨在提高处理器的并发性能和利用率。 |
那么多快才叫快呢?一个好的基于软件的交易系统,最小的开始到结束的时间最好在 2.5 us 左右。
低延迟编程
When in doubt, use brute force.
- Ken Thompson
Carl 在 presentation 中介绍了一个例子,如下:
1 | // 尽可能避免这种写法 |
上述例子的思路也非常清晰,在允许交易的时候尽快进入交易代码。
下一个例子是关于是否使用虚函数来读取配置文件的,虚函数用起来非常方便,但是有时候会带来比较大的开销。因此,一种可能的解决方式是通过模板来实现,这样可以消除一些分支和不被执行的代码。下图是一个例子:

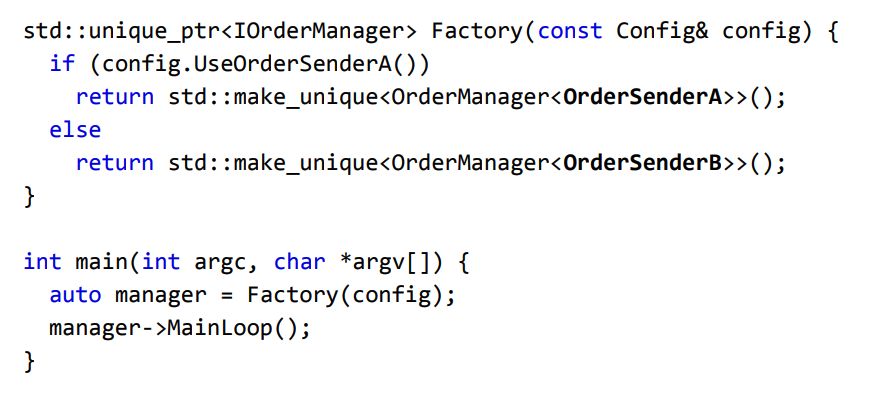
采用模版函数来实现能够保证在编译时所有的行为都是确定的。保证函数在运行时的确定性是非常重要的。
内存分配这一行为开销很大,所以很多对性能要求比较高的系统通常会使用一个预先分配好的内存池。复用对象比销毁释放对象要好,销毁对象也会带来很大的开销。复用对象还能够避免内存碎片。如果一定要销毁一个比较大的对象,那么使用其他线程去执行会是一个更好的行为。
C++中的异常本身不会带来太大的开销,如果 exception 不被抛出,这基本不会带来什么开销,但是如果我们使用 exception 来做流程控制,那么这个过程就会带来很大的开销。
在代码编写过程中,尽管分支是一种不可避免的逻辑,我们也应该尽可能避免分支,转而采用模版的方式来实现,下图是一个例子:


多线程是一个非常好的工具,但是多线程会带来很大的开销,比如:通过锁来同步数据的开销很大、lock free 的代码在硬件层面依然需要通过锁来实现、并行执行非常复杂、生产者很容易意外地使消费者饱和。如果一定要使用多线程,那么要尽可能少地使用共享数据,尽可能通过数据副本来传递数据而非直接共享,如果不得不共享数据,尽可能不要使用同步。
在数据查找场景下,尽可能通过保存数据副本来避免数据查找。
接下来介绍一下unordered_map的使用,大家都知道 map 是通过多个 bucket 来管理 key-value pair,我们应该尽可能保证一个 bucket 只有一个 key-value pair,因为 bucket 下的 node 是通过指针管理的,显然没有连续内存空间的访问效率。我们可以使用一些特殊的 map 实现来替代,比如 Google 的 dense_hash_map,由于其利用的连续的内存空间,整个访问效率会高很多。
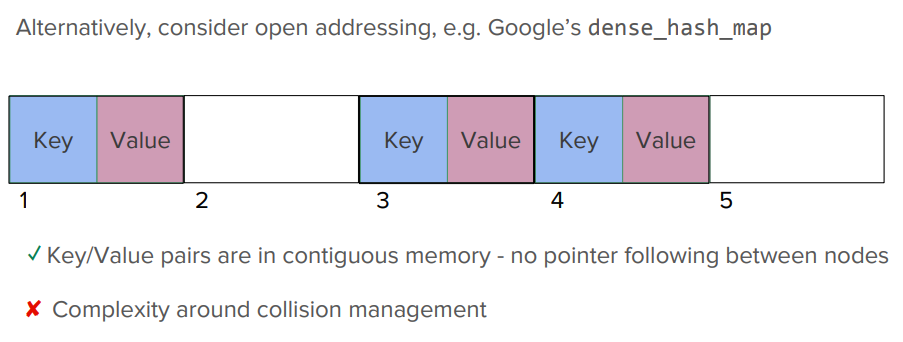
这里还提到一种方式,可以采用链式访问和连续内存空间的混合方式来实现,从而获得确定性的内存访问行为。下图是具体的实现:
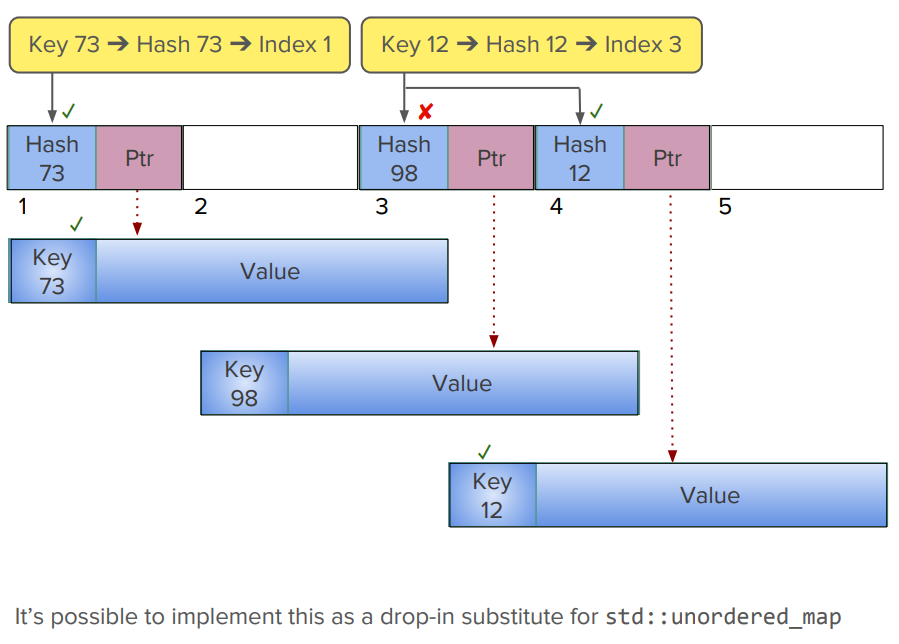
这种实现将连续内存空间作为 metadata,存储着指向特定对象的指针,这样可以保证比较确切的一次指针跳转即可获得目标对象。这样可以带来很大的性能提升。
hotpath 往往很少被执行,这导致 cache 往往被非 hotpath 占据,所以最好通过一些 dummy path来持续执行 hotpath,以保证 hotpath 尽可能多的占据 cache,这样也能让硬件在做分支预测时做出正确的决定。
在使用 CPU 时,尽可能不要共享 L3 cache,保证只有一个核能够访问 cache。如何一定要允许多核访问,那么尽可能讲一些可能干扰 cache 的程序移到其他 CPU 上。
Placement new有可能降低性能,因为它会对传入的内存执行一个空指针检查,可以采用如下方式替换:
1 | // Placement new |
1 | "Placement new" 是 C++ 编程语言中的一个概念,用于在已分配的内存块上构造对象。通常,使用 "new" 运算符可以动态地在堆(heap)上分配内存并构造对象。然而,有时候我们需要将对象放置在已经存在的内存块中,而不是动态地分配新的内存。这就是 "placement new" 的用途。 |
std::function也会发生 allocation,可以考虑使用inplace_function


std::pow也会带来比较大的性能影响,当执行 pow 操作时指数变大时,消耗的时间会发生巨大的变化

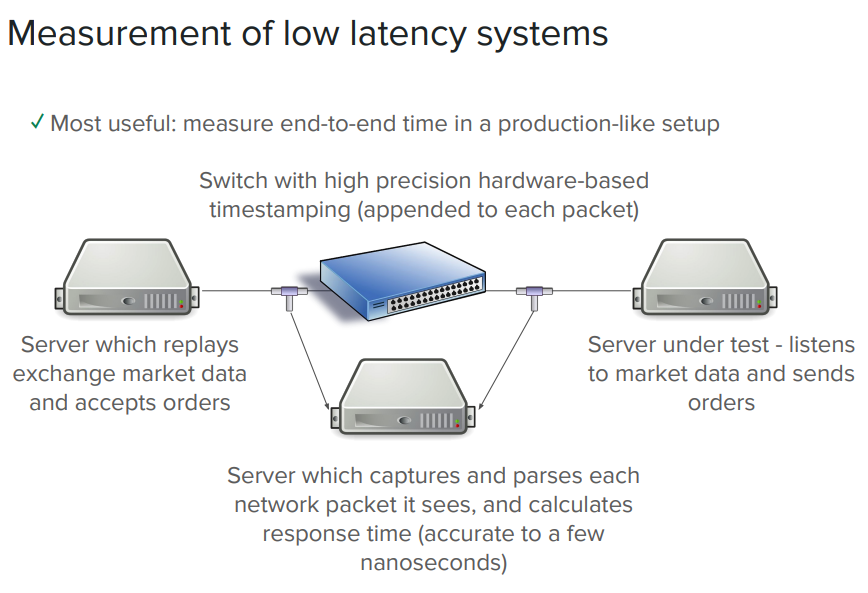
低延迟系统的性能评估
两种通用的方式:
- Profiling:检查 code 在做什么,瓶颈是什么
- Benchmarking:对系统用时进行评估
Profiling 可以找到一些非预期的行为,但是 Profiling 中做的优化不一定百分百让系统变快