读字节技术文章《广告案例|10亿数据、查询<10s,论基于OLAP搭建广告系统的正确姿势》
这篇文章是昨天刚放出来的,还挺巧,前段时间我刚好在面试过程中被面试官问到这个系统的相关问题。我们借这个机会,正好深入看一下这篇文章。
业务背景
精细化营销是广告系统中极为重要的一环。依赖于客户画像平台对用户画像的精确标注,广告系统可以针对性地进行广告投放,实现所谓精准投放的效果。这个过程中,分析师需要通过用户标签进行人群圈选,以挑选出最合适的目标用户群体。对于这类操作,业务方自然是希望能够更加高效地获得更加实时的圈选结果。因此,这类平台会遇到两方面的问题:
- 第一,由于此类查询分析是临时性的,各种标签组合数巨大,离线预计算无法满足此类灵活性。
- 第二,由于此类查询是实时场景,查询性能变得非常关键, 通常一次查询在分钟级,耗时较长,无法满足分析师需求。
这篇文章介绍了如何在 OLAP 场景下解决人群圈选查询的需求,并介绍了 ByteHouse 的使用。在 10 亿级用户测试数据下,整体查询 P99 小于 10s。
整体架构
整个业务系统的数据架构如下:
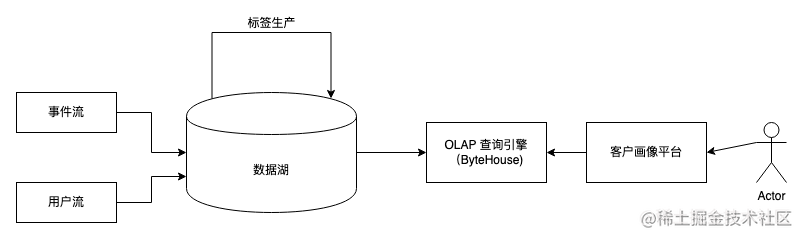
系统的输入分为用户流和事件流,用户流主要包含用户的注册信息,事件流则是用户的行为信息。标签生产任务则是异步执行,为每个用户打上标签。完成标签生产后,数据会被写入 OLAP 引擎中,用于满足灵活的查询需求。
数据湖中的数据格式如下所示,主要包含用户的基本信息和标签信息:
为了方便用户圈选,还可采用以 tag 为主的数据格式,如下所示:
这种格式的好处在于能够减少数据规模,只保留标签和相关的用户 id,方便用户圈选的相关操作。这里其实比较好奇他们是怎么管理用户 id 的,结果马上就来了。为了管理这些信息,这里采用了 ByteHouse建表,这里可知用户 id 是采用 int64 类型来存储的。
1 | CREATE TABLE id_tags ( |
在进行人群圈选时,比如需要找到满足多个 tag 的人群数量,可以采用如下 SQL:
1 | WITH (SELECT active_users as tag_1 |
这一操作需要进行全表的扫描,找到特定 tag 后在获取用户交集。然后再取长度。通过选取BitMap来实现,能够有效优化查询效率,建表语句如下:
1 | CREATE TABLE id_tags ( |
查询语句如下:
1 | SELECT bitmapCount('tag_1&tag_2') |
通过位图查询,能做有效优化这种查询的查询效率,这里给出的数据是 10 到 50 倍性能提升。
BitMap在 BitHouse 中是如何管理的
接下来我们来看看 BitMap 在 ByteHouse 中是如何管理的。正常来说,BitMap 的数据规模是跟随者需要映射的用户空间来线性增长的。比如采用 32 位 INT 管理用户 ID 时,对应的位图则是 2^32 bits(512MB)的空间。由于用户量往往无法达到这个数据规模,所以这里采用了一个叫做 Roaring Bitmap 的数据结构来做数据压缩。来看 chatGPT 介绍一下:
1 | Roaring Bitmap是一种高效的数据结构,用于压缩稀疏位图数据。它被设计用于处理大型数据集中的集合操作,如并集、交集和差集,同时具有较低的内存占用和高性能。Roaring Bitmap在处理大量离散值的数据时特别有用,比如在大数据分析、数据库系统、搜索引擎和网络流量分析等领域。 |
关于 roaring BitMap 的具体实现,大家可以看这篇文章
另一个优化则是通过字典对数据进行编码,优化查询效率,下面是开启字典优化的方式:
1 | CREATE TABLE id_tags ( |
有了字典之后,再进行交并补操作的效率就会高很多。
ClickHouse 在字节广告 DMP & CDP 的应用
在查找文章相关的内容时,我碰巧看到了这篇文章,同样也是介绍 ClickHouse 在字节广告中的应用。这里介绍了广告业务下的三个场景:人群预估、人群画像和统计分析:
- 人群预估主要是根据一定的圈选条件,确认命中的用户数目。在广告精准投放过程中,广告主需要知道当前选定的人群组合中大概会有多少人,用于辅助判断投放情况进而确定投放预算。因为是在线业务,一般要求计算的时间不能超过 5 秒。
- 人群画像主要是对广告投放的用户群进行画像分析,也是在线的,同样对时间有一定的要求,因为是偏分析的场景,一般不能超过 20 秒,否则用户的体验就非常差了。
- 统计分析的使用场景比较多,在线、离线都有,包括一些搜索词统计分析,广告、投放收入数据的分析等等,应用的方面很多。
这篇文章主要介绍了上面所说的人群圈选这一场景下业务迭代的整个过程,前期采用过明细存储的方式管理用户标签和 uid 的 mapping 关系,虽然他们通过各类方式对计算进行了优化,但是仍然存在一些问题,比如人群过大时查询效率低下,查询语句过于复杂等。最终才优化到了上文所说的方案。下图展示了 SQL 语句的优化:
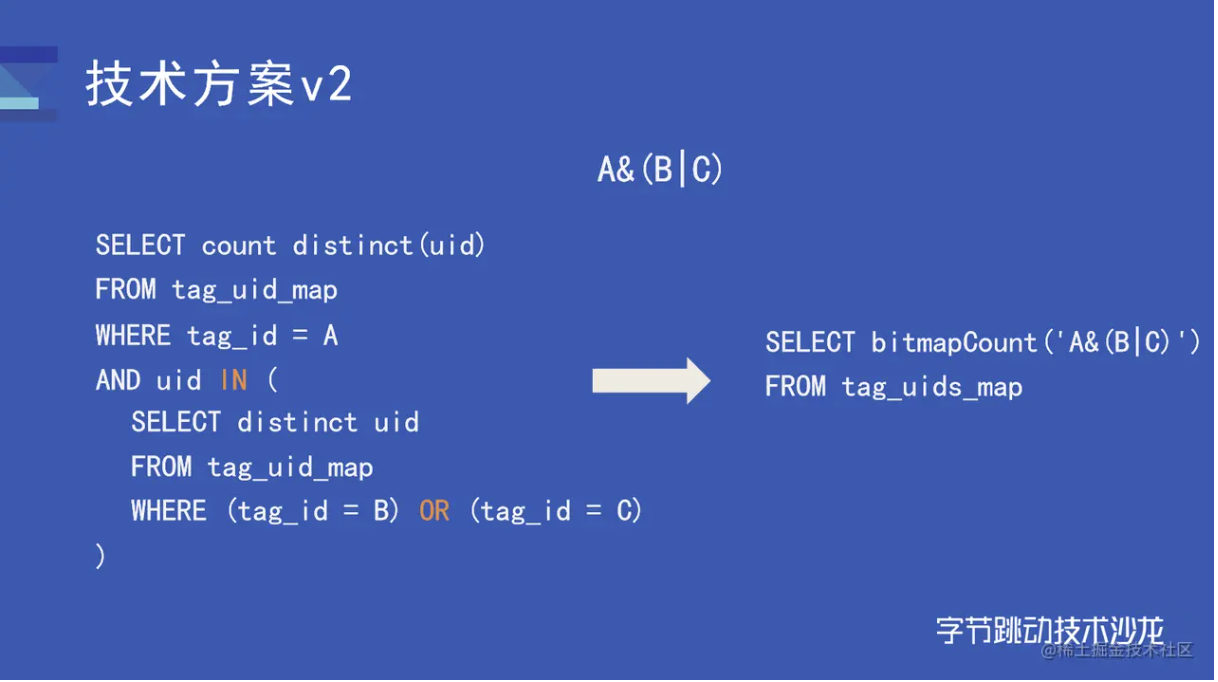
为了进一步优化整体的效率,这里还做了数据分割、并行计算的方式对位图查询进行优化。为了解决数据区间内用户 id 过于离散的问题,他们又对区间内数据进行了编码,从而使区间内的用户相对集中,这应该就是上文所说的“字典优化”了。
另外,文中还提到了通过 cache 进行数据读取和计算的优化,包括读取层面的 cache、中间计算过程的 cache 和最终结果的 cache。
这一系列的优化带来了非常明显的效果。文中提到“从空间上来说,采用 RoaringBitmap 可以减少 tag_id 列的冗余存储,同时 uid 采用压缩存储,因此整的空间存储降低为原来的 1/3,因为数据量降低了,因此导入也变快了,导入时长也缩短为原来的 1/3,同时,在查询性能上收益非常明显,avg/pct99/max 下降明显,消除绝大多数 5 s 以上的大查询,可以说达到了开发的预期。最后,在资源上效果也很不错,CPU 使用下降明显,内存使用上 PageCache 节省 100 G+ 以上。。。,原来确实是经常有一些大的查询,有些时间久的甚至超过了 20 s。上线后。。。很少看到超过 5 s 的查询了,绝大部分查询非常稳定。这个其实还是我们没有上中间结算结果 cache 时候的效果图,当我们通过 multiCount 缓存中间结果后,直接把 qps 下降了 4 倍以上”
对于他们的下一步工作,这里提到了三个方面,一是优化数据读取,有点类似于谓词下推的思路,二十智能化 cache,对公共子项进行缓存,三十扩充表达式的表现能力,优化使用方的使用体验。这几个思路说起来其实都是比较合理的优化方向。
Reference
[1] https://mp.weixin.qq.com/s/8ws9sqlTVHjDa_VHbe62Sw
[2] https://juejin.cn/post/6859570827051368462
[3] https://cloud.tencent.com/developer/article/1136054
[4] https://juejin.cn/post/6859570827051368462