OceanBase: A 707 Million tpmC Distributed Relational Database System
时隔几周,又来更新了。这几周时间比较碎片,没有找到比较好的机会写文。话不多说,开整。
今天这篇文章是还是 VLDB 上的一篇文章,主要讲了 OceanBase 的整体架构和设计经验。主要包括 OceanBase 的设计目标、设计标准、整体架构、关键组件以及相关的设计经验。主要分成下面五个部分,这篇文章也主要从这五个部分来展开:
- OB 的设计目标和标准、系统架构、SQL 引擎以及多租户实现
- OB 使用的基于 LSM tree 的存储引擎、非对称读写设计、增量压缩和副本类型等
- OB 的事务处理引擎、隔离级别和复制表
- TPC-C benchmark test。这个噱头十足,等下可以仔细看看。
- 构建 OB 过程中的设计经验
从技术选型来看,OB 使用了分布式数据库系统中常用的一些技术:LSM tree、Paxos等等,当然这部分各种分布式数据库的实现都是大同小异,没有最完美的设计,只有尽可能贴近当前业务场景的Best Practice。
老规矩看下 chatGPT 怎么说。
1 | OceanBase是由中国阿里巴巴集团开发的分布式关系型数据库系统。它是阿里巴巴公司的自主研发项目之一,旨在满足其海量数据存储和高并发访问的需求。OceanBase在设计上借鉴了Google的Spanner和F1等分布式数据库系统的一些思想。 |
整体设计
OB 的设计目标是为了在商用级硬件上构建可快速伸缩的高性能、低成本数据库,需要满足可跨区域部署、错误容忍等需求,OB 需要兼容常见的主流数据库,这也和设计 OB 时的时代背景有关,如果没记错应该是在 10 年前后,当时国内也没有像现在一样百花齐放,淘宝当时使用的主要还是 Oracle、MySQL 之类的数据库产品。(这个时间点我刚上大学,完全没有意识到波澜壮阔的中国互联网时代正在拉开帷幕)
首先是 OB 的设计目标,主要有以下几点:
- 支持在商品级硬件上快速伸缩,满足高性能和低成本的要求(这主要是因为 Oracle 真的太贵,卡脖子了)
- 跨区域部署和错误容忍,说白了就是要高可用。
- 兼容主流数据库(因为不兼容的话业务方就不想迁移过来了)
整体来说,这几个设计目标很符合当时的业务背景。
接着是设计标准,对于一个新的数据库而言,总要面临以下挑战:
- 业务的迁移成本和风险
- 业务方的学习成本
- 第三方服务提供者的学习成本
为了应对这些挑战,OB 定下了以下的设计标准:原生兼容主流数据库,考虑各种大中小组织的需求。对各种主流数据库的兼容能够降低业务方的迁移成本和学习成本,适用不同规模组织能够最大成都满足各类业务场景的成本和性能要求。
下面我们来看下基础架构,OB 支持 shared-nothing 架构,如下图所示,这其实是一个很标准的存算分离的架构。应用层发送请求到 proxy 层,由 proxy 层转发到对应的 db 节点,db 节点主要负责计算逻辑,由存储引擎访问底层的存储集群。
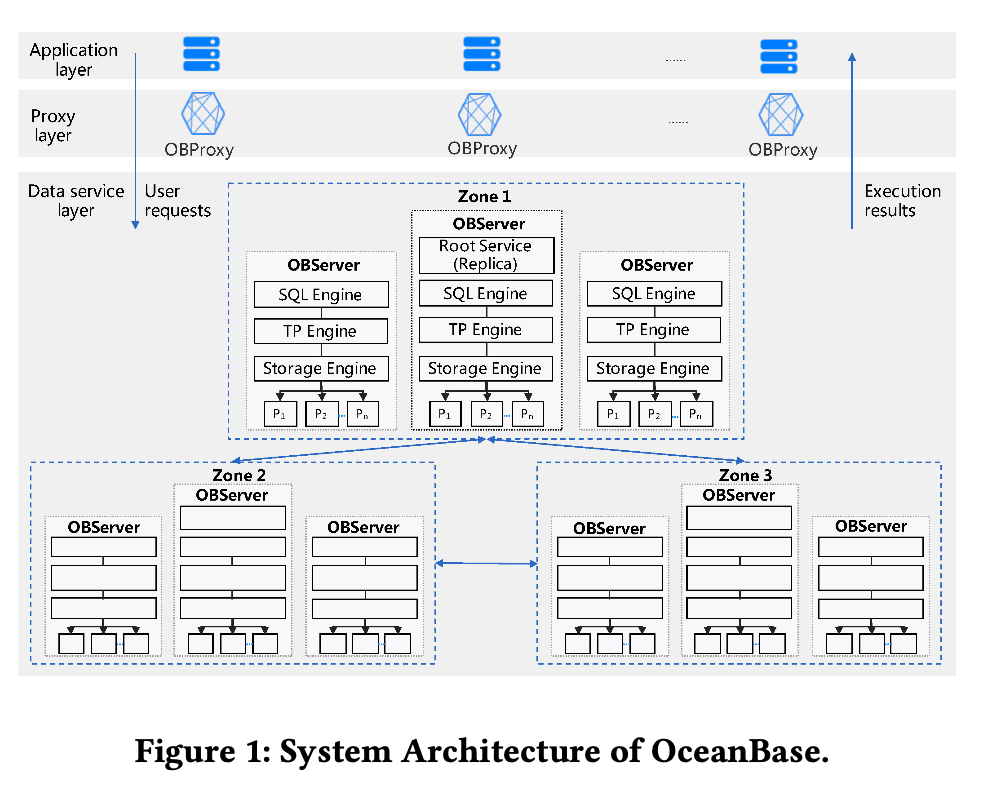
每个 OB 集群由多个不同的 zone 组成,不同的 zone 可以部署到单个 region 或者多个 region。在单个 zone 内,OB 是以 shared-nothing 的方式来部署的。Database 被切割成多个分片,这些分片是数据分布和负载均衡的基本单元。每个 partition 在每个 zone 都有一个副本,zone 与 zone 之间通过 Paxos 来同步。
单个 OB 节点和传统的关系型数据库差不多,接收到 SQL语句后,会把语句编译成执行计划,本地计划直接执行,跨节点计划采用两阶段提交来实现,事务提交在 redo log 被持久化到多数的 Paxos 节点后。
OB 中有多个 Paxos 组,其中一个组负责整个集群的调度、负载均衡、节点管理、失败检测等工作。
1 | "Shared-nothing"是一种计算机系统架构和设计模式,主要用于构建分布式系统。在shared-nothing架构中,不同的节点(计算机或服务器)之间不共享任何主要资源,如内存、存储或处理器。每个节点都是独立的、自治的单元,其操作不会影响其他节点。 |
SQL引擎是数据库计算层的主要组成部分,SQL 请求到达时,一般会进行语法分析、语义分析、查询重写、查询优化,由执行器来负责执行。如果 SQL 语句涉及到大量的数据,OB 的查询执行引擎则会使用分布式查询执行、数据reshuffle、水平(垂直)并发执行、动态 join filter、动态分区裁剪、全局队列等优化逻辑来执行。
这里提到了一个优化逻辑,在生成执行计划时,OB 会使用一个轻量框架来进行词法分析,之后会尝试匹配缓存中的执行计划(文中也提到其他数据库也有类似的逻辑),相比普通的解析器而言,这种方式会快 10 倍左右。(这里应该是 bypass 掉了语法和句法检查)下图是 SQL 引擎整体的模块结构: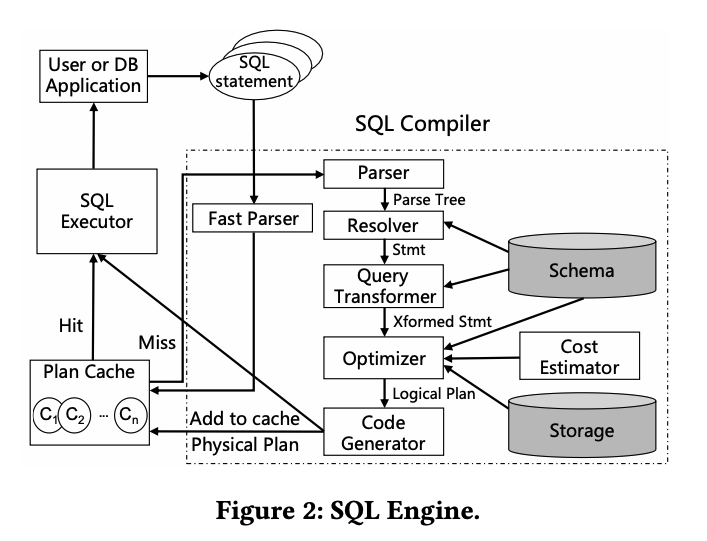
模块之间的协作是老生常谈,SQL 引擎接收到 SQL 请求之后,解析器对语句进行分词,安厚按照语法规则进行解析,Resolver 会把解析出来的 token 翻译成不同的对象,生成一个语法树;Transformer 会分析用于 SQL 语句的语义,尝试rule-based or cost-based 的语句重写,重写后交给优化器进行优化,生成最佳的执行计划。执行计划生成之后,执行器就可以开始执行。对于本地的执行计划,执行器仅仅会只会从执行计划顶部的操作者来开始执行,整个过程会在操作者自己逻辑之中完成并返回结果;对于分布式执行计划,执行器会吧执行树且分成多个可调度的 thread,然后通过 RPC 把它们发送到相关节点上来执行。
接下来是多租户的部分,OB 主要有两类租户:系统租户和普通租户。系统租户主要是维护系统层面的数据表、系统函数和其他系统管理相关的资源。普通租户可以被理解成一个 MySQL 实例,能够能够创建自己的用户、按需创建数据库和数据表、维护自己的元数据、还有独立的系统变量。多租户不仅需要满足逻辑上的隔离,更重要的是资源占用的隔离,简单来说,假如同一台机器上有多个租户,则不能因为某个租户的过度资源占用影响其他租户的使用。OB 里面比较取巧地用了 Docker container,但是文中提到 OB实现了自己的租户隔离,实现了内存、CPU 和数据资源、事务管理的资源隔离。(这里我理解是在 docker 上做了魔改,其实没有什么特别大的魔法)
存储引擎
OB使用的是非常流行的基于 LSM tree的存储引擎,这段的实现是一个非常标准的 LSM tree 实现,没有什么特别神奇的地方。文中提到了一个非对称读写,其实就是对读写配置不同大小的基本单元,读使用小的数据块,写使用大的数据块,这里其实我没太明白,说多个小的数据块能够合并成一个大的数据块,从而优化磁盘利用,以应对更大的写放大。接着就是 LSM tree 的compaction,这里做了一个优化就是只对写操作的数据块做 compaction,其他就是常规的 LSM tree 的 compaction,感觉没有什么特别的地方。OB 里面有多种不同的 replica,包括 full replica、data replica 和 log replica,下面是一个对比表:
事务处理引擎
这一段应该说是 OB 主要的卖点了,数据分片是数据分布、负载均衡、Paxos 同步的基本单位。每个数据分片(partition)有一个 Paxos 组,如下图所示:
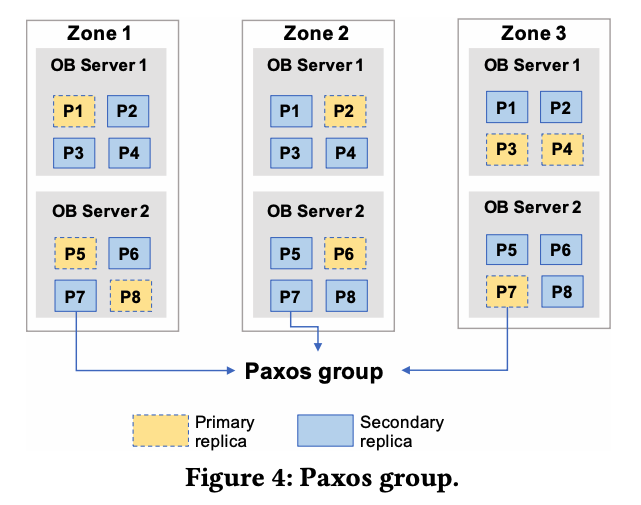
为了提供高可用的时间戳服务,OB 也将 Paxos 利用到了时间戳服务中,Paxos leader 通常位于数据表分片的相同 region 中,向 OB 的节点提供时间戳服务。
OB 的事务处理使用了一个典型的两阶段提交协议(2PC),两阶段提交可以说是数据库领域基础中的基础了,基础到现在已经都不会有人会在面试中问的程度。我们先复习一下:
1 | 两阶段提交(Two-Phase Commit,简称2PC)是一种用于确保分布式系统中事务的一致性的协议。在分布式系统中,由于数据存储在不同节点上,跨节点的事务可能会导致数据不一致的问题。为了解决这个问题,2PC协议引入了一个协调者(Coordinator)来协调参与事务的所有节点,以确保事务的原子性和一致性。 |
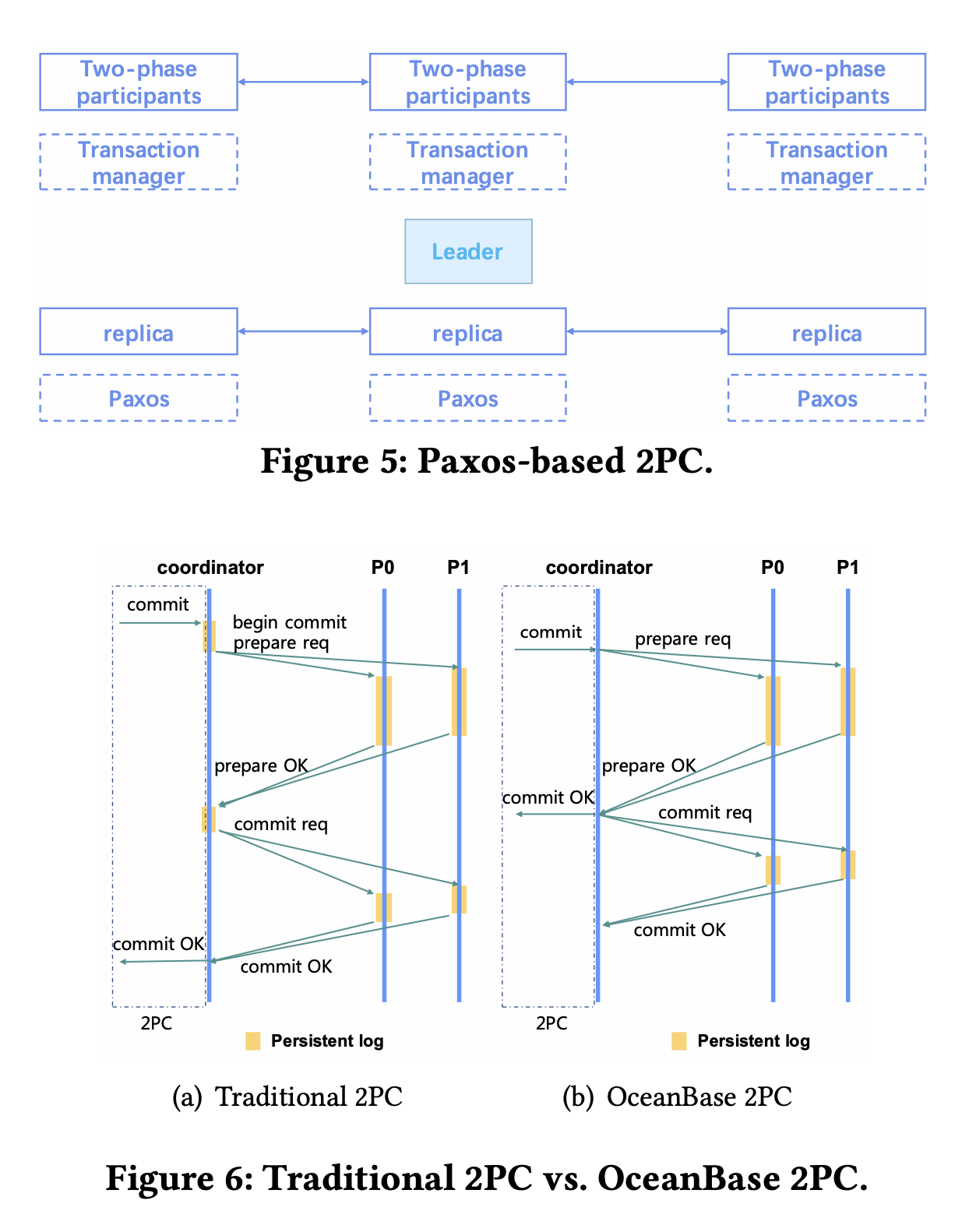
OB 把 Paxos 引入到两阶段提交中,如下图所示,在 OB 中,每个 2PC 的参与者都有一个 Paxos集群,在 2PC 过程中,如果某个参与者 fail 了,它可以直接切到自己的另一个 replica。这里还提到了一个优化,在传统 2PC 中,需要所有的参与者提交完成才能够返回提交成功,但是在OB 中,由于 Paxos 保证了参与者数据状态的可用性,OB 就可以在 Prepare 阶段完成之后就向 caller 返回成功,又 OB自己异步的完成 commit 阶段的工作。OB 支持读已提交和快照隔离的事务隔离级别。
OB 的设计经验
论文中总结了几个 OB 的设计经验,具体内容如下:
从 NoSQL 到 NewSQL
- 业务应用需要充分利用数据库本身的能力,而不应该简单地把数据库当作 KV 存储来使用
- 存储过程对OLTP应用仍然具有价值
- 分布式场景下,每个 SQL 查询和事务都应该设置超时,避免无限等待造成死锁
Both cost and performance
LSM tree 的架构天生适合进行数据压缩,数据压缩在付出一定程度 CPU 损耗的前提下能够大量减少存储所消耗的资源,甚至在 OLTP 场景下,数据压缩编码能够带来更好的 缓存命中率和 更低的 IO 开销。这里提到支付宝从 Oracle 迁移到 OB,整个数据量从 100TB 降到了 33TB
分区和分片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22Partitioning(分区)和Sharding(分片)都是用于处理大规模数据的方法,它们在分布式系统中被广泛使用,但它们在具体的概念和实现上有一些区别。
Partitioning(分区):
分区是将数据划分成更小的逻辑单元,称为分区或分片。每个分区通常包含一部分数据,这样可以将大规模的数据集分解成管理较小的单元,使得数据的存储和处理更加高效。分区可以根据数据的某种属性或键值进行,以确保相关的数据存储在同一个分区中,从而提高查询性能和数据访问的效率。分区可以在单个服务器上实现,也可以在分布式系统中使用。
Sharding(分片):
分片是将数据水平拆分成多个独立的数据集,每个数据集称为一个分片。每个分片都存储着部分数据,并且在分布式系统中通常被分布在不同的服务器上。通过分片,可以将大规模的数据集分散到多个节点上,从而实现数据的分布式存储和处理。分片可以基于不同的策略进行,如哈希分片、范围分片等,目的是平衡数据的负载并实现数据的水平扩展。
区别:
1. 数据范围:
- 分区是将数据划分为逻辑单元,通常是为了管理大规模数据集,可以在单个服务器或数据库中实现。
- 分片是将数据水平拆分为多个独立数据集,通常用于在分布式系统中分散数据存储,实现水平扩展。
2. 存储方式:
- 分区通常是逻辑上的划分,并没有实际分散数据存储的概念。
- 分片是实际将数据分散存储在不同的节点或服务器上。
3. 目的:
- 分区旨在提高数据管理和处理的效率,减少数据访问的负担。
- 分片旨在实现数据的分布式存储,以支持大规模和高并发的应用需求。
虽然Partitioning和Sharding在某些情况下可以用来指代相似的概念,但在分布式系统的背景下,它们通常代表了不同的数据处理和管理策略。这里着重提了一下分区和分片的区别,从文中的介绍来看,分区具有逻辑性,比如基于 column 分区,而分片则完全依赖于 hash,不存在逻辑上的区分。相比分片,分区主要有以下好处:
- 优化使用。分区不可用并不意味着对象不可用,查询优化器可以自动将无法引用的分区移除。其实这句话很 confusing,我的理解是,比如在基于列分区的场景下,有些列不可访问并不会影响不涉及这些列的查询。但是直接通过哈希分片则无法满足这个要求。
- 更方便地管理对象。分区可以分别管理,各类 DDL 语句可以在分区上执行。
- 减少资源争用,我的理解是分区是基于逻辑关系来切分的,所以相对应的共享资源争用就会少一些。
- 优化查询性能,分区键可以一定程度上实现数据过滤。
- 优化负载均衡。逻辑分区的好处是可以基于业务场景进行数据的均衡存储,直接简单的哈希分片则无法优化单点过热的问题。
互联网公司和非互联网公司
互联网公司面临更多的高并发场景,所以对数据库产品的性能需求会高很多,OB 避免传统数据库的一次性升级,转而采用灰度升级的方式来削弱风险。其实这个地方的描述有点灌水的感觉了,现在只要是大规模集群,基本都会采用灰度发布的方式。当然,不排除还有一些传统公司仍然使用单点数据库服务。
下图是 OB 的演进历史,大家可以看一下,以作了解: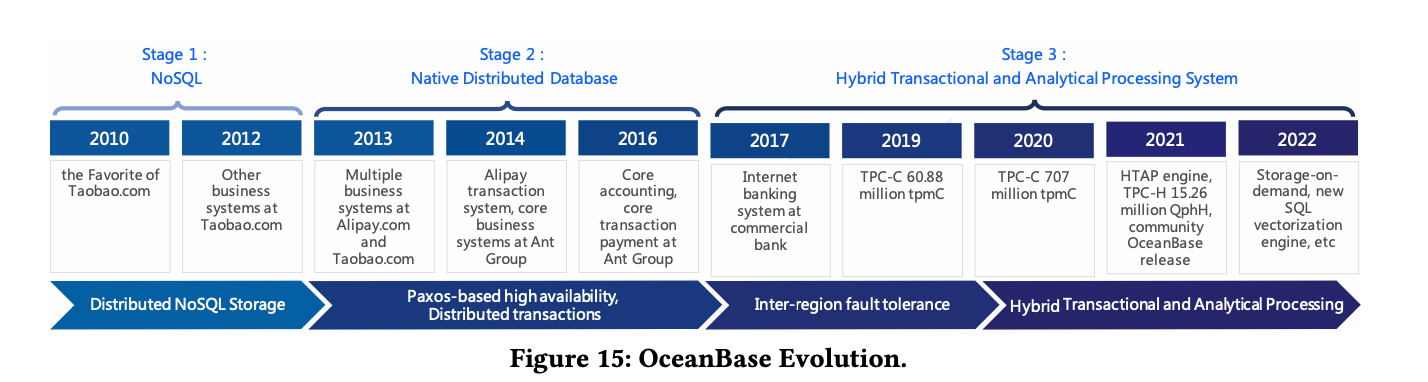
文中还描述了 OB 做的 TPC-C 实验的具体数据,感兴趣的同学可以看看原文。