(Paper Reading) SQLite: Past, Present, Future
SQLite: Past, Present, Future
这篇文章是 22 年 VLDB 的一篇文章,文章主要介绍了 SQLite 的历史沿革及在 OLAP 领域的应用和优化。
我是第一次听说DuckDB这个名字,问了一下 chatGPT,下面是 chatGPT 的回答:
1 | DuckDB是一个开源的内存列存储数据库管理系统(DBMS),专为高性能和低延迟的分析查询而设计。它的目标是提供类似传统数据库系统的SQL查询能力,同时在处理大规模数据集时保持快速响应时间。 |
这篇文章主要贡献如下:
- 介绍了 SQLite 的历史沿革
- 对 SQLite 的特性进行了系统的评估
- 在数据分析工作场景下对 SQLite 进行了优化
- 确定了一些嵌入式数据引擎性能衡量指标
- 对未来 SQLite 的进一步性能优化进行了方向性的叙述
下面按照文章整体脉络梳理一下文章的内容。
SQLite 的架构
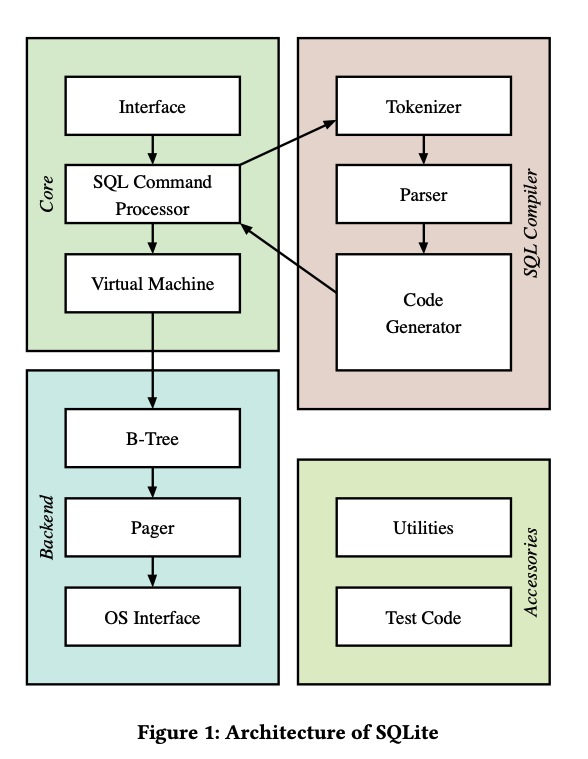
SQLite 主要包括四个大的模块:
- SQL Complier:SQLite 中 SQL 编译模块的运行类似一个编译器,通过词法分析、语法分析和语义分析来编译 SQL 语句,形成一个字节码的可执行程序,由一系列虚拟指令构成。
- Core:SQLite的核心执行引擎负责处理所有数据库的底层操作。它以一个虚拟机的形式存在,会对 compiler 生成的字节码逐一执行。
- Backend:存储引擎,负责将数据持久化磁盘上。SQLite使用B树(B-tree)作为其默认的存储引擎,包括索引 B 树和表 B 树。B树是一种用于高效存储和检索数据的数据结构,它允许快速的索引查找和范围查询。 SQLite 使用叫做虚拟文件系统(virtual file system, VFS)的抽象对象来实现不同操作系统的可移植性,对于不同的操作系统,它会有不同的 VFS。
- Accessories:SQLite的附加模块,包括一些 UT 和工具函数:包括内存分配、字符串操作、随机数操作等。
事务
SQLite 是一个支持事务的数据库引擎,通过回滚和 WAL 模式,能够满足 ACID 四个特性。(这是面试数据库团队经常会考到的一个八股文)
回滚模式
在回滚模式中,SQLite 在执行事务时需要获取数据库文件的共享锁,当事务涉及对数据库的更改时,SQLite 就会将读锁升级为保留锁(reserved lock),从而阻塞其他写入的事务,但是仍然允许读操作。在执行写操作前,SQLite 会创建一个回滚日志。对于每个页面,SQLite 会将其原始数据写入回滚日志,并将更新后的页面保留在用户空间。当 SQLite 提交事务时,它就会把回滚日志刷入持久化存储。然后,SQLite 会获取一个数据库文件的排他锁,用来 block 其他的读写操作,同时写入当前更改。更改后的页面会刷入持久化存储中。回滚日志接着会通过多个机制中的某一个来作废掉,取决于日志模式。在 DELETE 模式中,SQLite会将回滚日志删除掉,但是由于删除操作本身成本较高,SQLite 同时也会提供其他方式来使日志无效,比如在 TRUNCATE 模式中,回滚日志会被截断而非删除;在 PERSIST 模式中,会被日志头会被覆写成 0。作废回滚日志操作会提交当前事务。最后 SQLite 会释放这个排他锁。
1 | Note: 在SQLite中,"reserved lock"(保留锁)是一种用于数据库文件的文件级别锁定机制。它是SQLite中的一种锁定状态,用于控制对数据库文件的并发访问。 |
WAL模式
Write-Ahead Log(WAL)是数据库中另一个重要机制,概念上属于回滚模式的倒置。回滚模式试讲原始页面内容写入回滚日志,然后在数据库文件上修改页面数据。而在 WAL 模式中,SQLite则是维护原有页面数据,而将修改信息写入到单独的 WAL 文件中。当开始一个事务时,SQLite 会记录最后一次有效提交的位置,作为 end mark。当 SQLite 需要一个页面时,它会尝试搜索 最近版本的WAL。如果页面不存在于 WAL 中,SQLite 就会从数据库文件中拉取页。对数据库的修改会仅仅写入到 WAL log 的最后面。这里就会提到一个 checkpoint 机制,当某次提交导致 WAL日志达到某个特定大小时,SQLite 就会将WAL 中更新的页面写回数据库文件。在提交之后,系统也不会直接删除 WAL 文件,而是会反复写入 WAL 文件,以达到文件复用的目的,降低因新建WAL 文件等操作带来的开销。(这个机制有点类似于循环缓冲区的实现逻辑,类似思想在很多其他场景也有应用)
WAL模式有两大优点:第一可以显著提高并发度,因为读操作仍然可以继续执行,只有在 WAL 提交时才需要阻塞读。第二就是 WAL 由于减少了对持久化存储的写入操作,它明显更快一些。
但是 WAL 同时也有不可忽视的缺点。为了加速 WAL 的搜索,SQLite 在共享内存中创建了 WAL index,用于优化读事务性能。但是,共享内存要求所有读都要在同一台机器上。另外 WAL 模式无法在网络文件系统中工作;在进入 WAL 模式后,我们也无法修改页面大小(?)。另外 WAL 模式也增加了系统的复杂复,包括 checkpoint 操作和其他与 WAL 相关的操作。
SQLite 的workload 和硬件变化
过去这些年,随着电子设备不断发展,SQLite 运行的平台也发生了很大的性能变化,与此同时,基于对 SQLite 使用的统计,SQLite 的使用场景和最初涉及目标场景已经有了很大的区别,一部分是简单的键值对查找,然而存在一个长尾场景,有许多复杂的 OLAP 操作也运行在 SQLite 中,这些 query 里面有很多都会涉及到多张表的 join 操作。此外大概有 25% 左右的语句涉及到数据库的写操作,大部分写是 UPSERT 操作。
1 | 当涉及JOIN操作时,数据库系统通常会使用以下算法和技术来实现不同类型的JOIN: |
现在的硬件扩展对 SQLite 的性能有了更高的要求。SQLite 一般不使用多线程,以达到更高的性能。为了给海量数据排序,SQLite 可以选择开启一个多线程的外部归并排序。对于其他操作,SQLite 一般直接在调用线程中完成。这种设计能够最小化其他线程的资源竞用。正常来说,SQLite 与其他 OLAP 数据库相比并不具有竞争力,但是 DuckDB 集成了向量化引擎和并行查询处理,给 DuckDB 提供了良好的 OLAP 性能。
1 | 向量化引擎(Vectorized Engine)是一种优化技术,用于执行数据处理和计算任务。它是在现代计算机体系结构中针对数据密集型操作的一种高效执行方式。 |
性能评估实验
作者接下来使用 SQLite 和 DuckDB 来评估不同场景下的性能。首先使用了 TATP benchmark 来评估 OLTP 场景下的性能。由于 DuckDB 主要是设计满足 OLAP 场景下的需求,因此其吞吐量在实验中远远不及 SQLite 的吞吐量。在数据规模达到百万级别时,SQLite的在 Cloud server 上的TPS能达到 10k左右,比 DuckDB 高了几个数量级。接着又使用了 Star Schema Benchmark 来评估了 OLAP 场景下的性能。在这一场景下,DuckDB 展示了极佳的性能,在延迟上 比 SQLite 快了 10 倍到数十倍不等。
为了理解这一性能差距,作者同时对 SQLite 的执行引擎做了profiling,分析得出主要是SeekRowid和Column操作耗费了大量时间。SeekRowid是为了在 B-tree 上找到对应 row id 的行,用来执行 join 操作;而 Column是为了提取给定记录的列值。基于这一结果,作者给出了两个关键的优化目标:避免不必要的 B-tree探测同时流化值提取过程。
避免不必要的 B-tree 探测
SQLite 使用嵌套循环来实现 join 操作,内循环往往可以通过索引来加速。为了优化 join 操作的效率,作者通过布隆过滤器来实现 SQLite 的Lookahead Information Passing(LIP)。说白了其实就是通过布隆过滤器来加速 join 操作中对内表的检索操作,使用布隆过滤器后,实验观测到可最多十倍的性能提升。
1 | 在数据库领域中,Lookahead Information Passing(LIP)是一种查询优化技术,用于改善查询执行的效率和性能。 |
流化值提取过程
这部分逻辑相对应的会涉及到更具体的 SQLite 存储模式。SQLite record 由两部分组成:header 和 body。header 中存储了记录的类型码等元数据信息,body 中存储了记录的数据信息。为了提取值信息,SQLite 首先回到 head 里面找到一个指针,然后通过header 中的类型码遍历数据,直到找到对应的列。这种模式显然不适合 OLAP 场景下的流化数据提取。作者也尝试了其他方式去优化其数据提取过程,但是为了避免破坏 SQLite 在不同平台的稳定性,作者放弃了这部分优化。
与此同时,作者又比较了BLOB 场景下的吞吐量,发现 SQLite 在 10KB 大小 blob 时吞吐量最佳,TPS 能够达到 9k 左右。随着 blob 的增大,其性能逐渐拉跨,甚至比不上文件系统的吞吐。这是由于 WAL 只允许 1000 个页,相当于大约 4MB 的大小限制,这带来了额外的写开销。
作者同时比较了SQLite 和 DuckDB 的资源使用情况,比较有意思的点是 SQLite 在load 实验数据时虽然最终产生的数据库文件大约是 DuckDB 的两倍,但加载时间明显快于 DuckDB,作者没有详细解释这是为什么。
在文章最后,作者提到了为什么没有对 SQLite 做 OLAP 场景下的优化,这是由于 SQLite 是一个通用型的数据引擎,为了保证不同场景下的性能和兼容性,不得不放弃一部分优化方式。然而,通过一些空间换时间的方式也能加速 OLAP 场景下的性能。通过向量化执行、数据压缩、运行时代码生成、和物化聚集等方式可以对一个传统的 OLTP 引擎进行 OLAP 场景下的优化,但是哪种方式能够最大化优化性能、哪些没有太大的优化价值,就需要这篇文章中的各类性能评估实验。这应该也是作者写这篇文章的动机。
总的来说,这篇文章介绍了 SQLite 大致的历史沿革、系统架构和性能评估数据,虽然创新性上感觉稍显不足,但是比较扎实地进行了一系列实验比较,为 SQLite 的优化提供了比较好的参考数据。